tl,dr
- Without requiring retraining, large language models can be used to answer questions about new or proprietary data.
- This requires Embedding Models (language models themselves) which map language into vectors
- A vector database, which stores the embedding vectors, can be queried for the relevant content from the document
- If you have done your job correctly, the relevant content is small enough to be sent to an LLM for question answering.
- We introduce Embedding models and review their ability to retrieve relevant content.
Introduction
Despite the fact that the technology has been around since flossing was a dance and not just a dental hygiene practice, Large Language Models were thrust into global significance with the inclusion of Reinforcement Learning with Human Feedback (RLHF). What we need to know about RLHF is that there was some pre-existing LLM, already crammed with all the knowledge of the public internet, that had to be locked up in the server room whenever visitors came around because it did not know how to behave in polite society! It was then sent to finishing school (technically it was fine-tuned) where it was rewarded with synthetic dopamine when it responded like the head girl and when it started sounding like a wild 4Chan user, it got a time out in the naughty corner!
While fine-tuning requires considerably less effort than training a model from scratch, the effort is still high. In the case of RLHF it involves finding enough text from enough head girls so the model’s raw sentence prediction ability is steered towards polite (ever surprised by how often ChatGPT apologises?) and engaging responses and away from the internet's more... fragrant corners that could steer this powerhouse off track.
Given the effort, we are going to postpone training or the fine-tuning of models until later articles. What we want here is a more gentle approach to the subject and, fortuitously, that approach exists. So buckle up, and let's dive headfirst into the wonderful, whimsical, and slightly less daunting world of Embedding!
Just enough theory to be dangerous
At their core, Neural Networks multiply vectors. Each layer in the neural network consists of a vector with a fixed length (dimension). If you want to put language into a neural network, you need a way to first turn it into a vector. This is the job of the embedding model, taking input text of various lengths, and turning it into a fixed length vector. The embedding model, while also a language model and probably sharing much of the architecture, is not the same LLM you are, no doubt, thinking about. For example, the OpenAI publishes and embedding model called “text-embedding-ada-002” while the LLM is something like “gpt-3.5-turbo” or “gpt-4” (confusingly, in generation 3, OpenAI also had a range of large language models called “ada” but these should not be confused with “embedding-ada” which produces vectors, not words).
If you are not running on auto-pilot, I hope you have spotted the key conceptual problem an embedding model needs to solve: the preservation of “information” as it is translated from language into a vector space. At a purely theoretical level, it is obvious that the dimension of the vector (coupled with the byte size of each element) will cap the amount of "information" that a vector can contain. Unfortunately, our understanding of the structure of language and how to abstract it into a mathematical space is at an early stage so choosing embedding models can often feel more like art than like science. It also means that for now, more dimensions are not necessarily “better”. OpenAI’s “text-embedding-ada-002” produces relatively high dimensional vectors (1536 dimensions). Many embedding models create vectors of dimension 768 but you can get smaller models that produce vectors in 384 or lower dimensional space.
The information that is contained in an embedding reflects the objective function that was used to train (or fine-tune) the embedding model. Models that have been trained on Question-Answer pairs may not be able to identify duplicates as readily as a model trained on Pair Classification data.
The final detail for now is that, under the hood, even these models do not take sentences or paragraphs or even words as direct inputs. The two terms used most frequently to describe the direct inputs into an embedding model are “tokens” or “word parts”. It is not all that surprising that we need access to parts, rather than complete words. Many words contain both their intent and their tense. Any mapping that preserves this information requires both. I bring tokens up for two reasons. Most importantly, all embedding models have limits on how many input tokens they accept, most also quietly truncate longer inputs. Any information that is truncated cannot, by definition, be contained in the vector embedding. This means, depending on your use case and your model, you may want to break your input text up into chunks, which contain “information” but do not exceed a maximum token length. In an ideal world, you should look at the data that was used to train your embedding model and try to get your text to match the length of that data, even if the model can handle more. In practice, no developer has time for that, so, upfront, just try breaking your inputs up in the easiest way possible and run a test.
The second point is that there is not only one way to tokenize. Tokens are chosen by looking at unique word parts that occur frequently in the training data. If you are working with text that contains a lot of technical jargon, with terms that do not occur frequently in the text that was used to build the embedding model, your embedding model may treat the jargon as “unknown” words. If the core of your problem is “unknown” to the model, your results will be underwhelming.
Embedding models are very useful. With a vector, we can perform mathematical functions. In particular, I can ask if two vectors are close. This turns out to be really useful in tasks like Translation, Classification, Retrieval, Semantic Textual Similarity or Summarisation. While Translation, Classification and Summarisation tasks are pretty much what they say on the can, now is as good a time as any to “define”:
Semantic Textual Similarity (STS): A score (think of a number between 0 and 1) for any two sentences, with higher scores showing the sentences are more similar.
Retrieval: Imagine a set of Frequently Asked Questions. For a given question, I want to (wait for it, wait for it, wait…) *retrieve* the answer.
Simple enough? But let’s not lose the lesson here. In STS, the “closest match” for the question “What is a rai stone?” would be “What is a rai stone?”. In a Retrieval problem, the “closest match” would be something like “The Yap islands group is part of Micronesia and has a very peculiar currency: stone. Stone money known as “Rai” are large stone disks, sometimes measuring up to 4 metres, with a hole in the middle that was used for carrying them. Rai was and is still used as a trading currency there.”
Now, armed with just enough information to be dangerous, Let's grab this tech bull by the horns and see where it takes us! Or, if you are Australian or enjoyed Netflix’s “Drive to Survive”, let’s FSU!
Getting new data into an existing LLM
LLMs are big. Have I mentioned that before? Yes? Well that’s because they are monstrous. Training them is not for the faint of heart or for people just looking to try something new. Also, once data has been trained into an LLM, it is available to all users, so building fine grained access control into a base LLM will prove difficult.
The implication of this is that, at least in the short term, Base LLMs will need to be shared by many users and will therefore need to be broad in scope and not contain sensitive data. Our game plan for specialised or proprietary text data (I will call this “New Data” to distinguish it from data that is already in the model’s training set) will involve storing the New Data in a database optimised for working with text and querying this with the user’s question (prompt). Both the user’s original question and the results of the search will be passed to the Base LLM for summarisation or just to make use of the fact that the Base Model’s fine-tuning (RLHF) was done to ensure its output is engaging to the user.
If someone put a gun to my head and said “Put this in a picture”, it would look something like this:
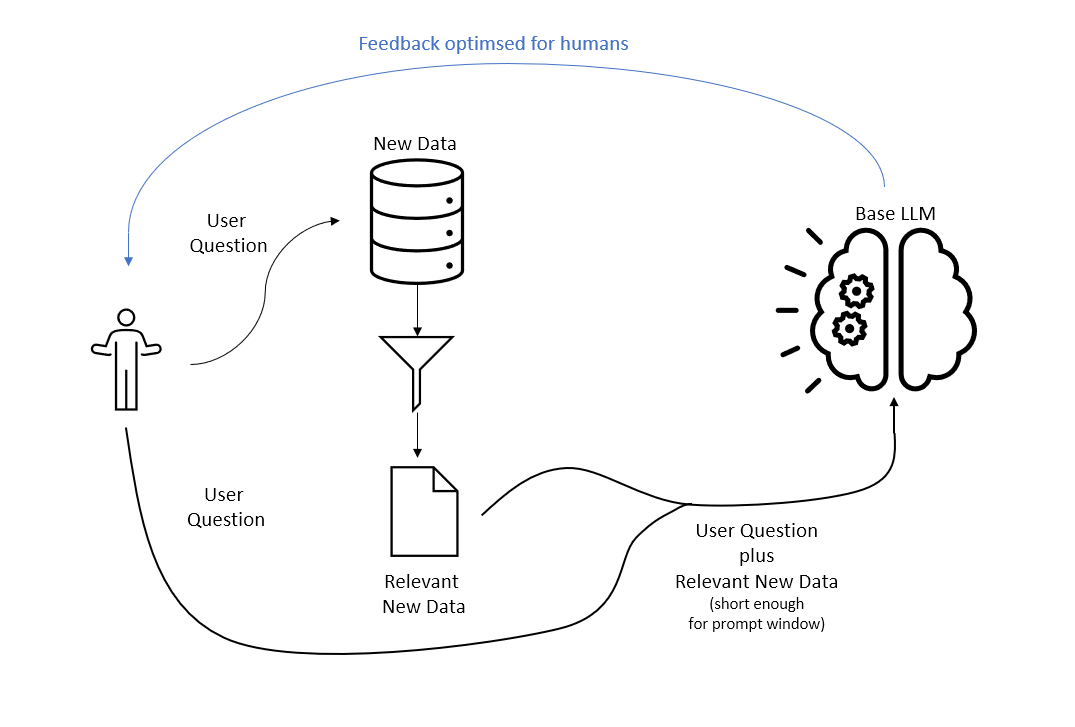
We therefore handle bulk New Data outside of the Base LLM, which only receives relevant, bite-sized chunks of the New Data in order for it to be packaged nicely to the user.
For proprietary data to stay proprietary, you still need to ensure that the relevant data that is sent from your data store to the Base LLM is secured - but you are smart enough to understand that already and your employer is rich enough to afford a good Base LLM in their own cloud subscription or GPU Cluster where all data entering the model is controlled (the correct response here is “Yes! Of Course that's how we do it”)
The Embedding Model is the thing that is used to create the New Data in a format that allows for search. That data is then stored in a Vector Database - more on these in a later instalment. For small examples, we do not actually require a Vector Database. We can use a simpler structure, something like a Pandas Dataframe but remember that the output of an Embedding Model is a vector of double point precision numbers (floating point precision needs to be discussed but not now, for now just note that that I am using the technical term “double point precision” fairly loosely). These vectors do not compress very well, so, especially if you split your text into many parts, you should still expect that embedding text data into a vector space makes the data much bigger.
And so, finally, we are going to stop talking about background and start working on our first example, the back-end of a question answering bot. I have published the relevant Jupyter notebooks to a github repository if you are interested. There are many other worked examples and discussions about question answering bots on the internet. To name just two good examples, or if you want to get into the details I am glossing over here, check out
- OpenAI’s very own example:
- Pinecone, the Vector Database company, has a number of articles on it but this one is as good a start as any.
Noting what I have said about data (see the ‘Your data sucks’ section of my preamble to this series) , I am going to circumvent 80% of the effort by selecting a clean dataset from Kaggle. In this case the data on Mental Health for a chatbot. The data is Canadian and has a lot of references to Covid. It consists of a csv file with three columns Question_ID, Questions and Answers, and there are 98 entries. It does have fairly lengthy answers so we get to test an hypothesis about input token length, truncation and the preservation of "information" (see the appendix in this post). Here are some statistics regarding the word count of the ‘Answers’ part of the FAQ
| Statistic | Value |
|---|---|
| Mean | 261 |
| Min | 16 |
| Max | 1453 |
The Hugging Face Massive Text Embedding Benchmark is a good place to start looking at Embedding Models. They have done a lot of work to assess models against benchmarks and have a framework where new models can be run through the same paces so hopefully the leaderboard remains up to date.
To get a comparison for how different embedding models perform, we will test the following models
* Except for “ada”, the maximum input length can be increased above the default but, since the models were trained on data of a certain length, captured in the default setting, longer inputs may degrade model performance.
Since the Kaggle data consisted of a list of Question / Answer pairs, one way to test the models would be to embed only the Answers and store them in a database. For each Question, I could query the database for the closest match (i.e. I am performing a form of Retrieval Benchmark Test). The model would get a point if the Answer returned from the database query matched the Answer from the Kaggle input data. Since there are 98 questions, the model would get a score between 0 and 98.
If I was using an Embedding Model and Vector Database to get New Data to an LLM as per my diagram, I would cast a wider net than just querying the top result. My second test was intended to capture this by looking at the 4 closest matches for every Question. Since the top 4 results contain the same top result used in the first test, the score for this second test would be at least as good as the score on the first test.
The table below shows the results of the FAQ Retrieval Benchmark Tests. The Disk Size in this table is the size of the csv file that contains the input Kaggle (text) data with an extra column that contains the embedding vector. Models with higher output dimensions obviously take up more disk space.
The results of this first test are not completely surprising (the surprise - at least for me - is presented in the appendix): “Different models perform differently” so be prepared for a lot of testing. The InstructOR models allow for some form of input prompt engineering depending on the task at hand. The e5 models use fixed but different approaches for embedding data vs. embedding queries. Ada and all-MiniLM-L6-v2 only offer one way to embed both documents and queries. A natural assumption is that, over time, the range of embedding models may increase and their relative performance will designate some for specific tasks. Even then you will need to test it on your data because MTEB benchmarks are good but a test on your data is better. Or, these models could all be rendered completely obsolete by some new understanding of the structure of language which will simultaneously make everything simpler and more effective. That would render the effort that went into producing this post useless. In some small way I guess that is how Kasparov or Lee Sodol felt!
Appendix: Testing an hypothesis and finding out I was wrong
Before writing any code, I had a hypothesis “Some of the answers in the Kaggle FAQ data were longer than the input token limit of some of the embedding models. Models with short input token limits (i.e. all-MiniLM-L6-v2) will perform better during lookups if I break up the Answers into smaller chunks before embedding”. To test this hypothesis I took each of the answers and split them into “paragraphs” using the newline character to delineate a paragraph. I separately embedded each paragraph. This increased the number of entries in my database from 98 entries with an average word length of 261 to 600 entries with an average word length of 43.
Turns out, my hypothesis was wrong, as the following table shows
While I only included the results for two models in the table, the results were in line for all the models I tested, chunking the Answers made the search worse.
This served up a piping hot plate of insight into the “preservation of information” as one takes the leap from language into the eerie vastness of vector space, which, in retrospect, is as clear as a summer's day. The “information” in a vector embedding, even from a small model, comes from more than just a sentence or bullet point. Don't mercilessly chop up your text into itty-bitty pieces just because you are worried about token length. We are running a fast food joint here, not a Michellin rated restaurant.